Kernel Methods
Kernel methods are powerful nonlinear techniques based on a nonlinear transformation of the data
 into a high-dimensional
feature space, in which it is more likely that the transformed data
into a high-dimensional
feature space, in which it is more likely that the transformed data
 is linearly separable. In feature space, inner products can be calculated by using a positive definite kernel
function satisfying Mercer's condition [14]:
is linearly separable. In feature space, inner products can be calculated by using a positive definite kernel
function satisfying Mercer's condition [14]:
 . This simple and elegant idea, also known as the ``kernel trick'', allows
to perform inner-product based algorithms implicitly in feature space by replacing all inner products by kernels. A commonly used kernel function is the Gaussian kernel
. This simple and elegant idea, also known as the ``kernel trick'', allows
to perform inner-product based algorithms implicitly in feature space by replacing all inner products by kernels. A commonly used kernel function is the Gaussian kernel
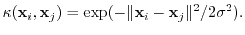 |
(1) |
In kernel-based regression techniques, a nonlinear mapping is evaluated as a linear combination of kernels of support vectors
 |
(2) |
Thanks to the Representer Theorem [1], the nonlinearity  can be represented sufficiently well by choosing the training vectors as the support
of this expansion.
can be represented sufficiently well by choosing the training vectors as the support
of this expansion.
 Pdf version (236 KB)
Pdf version (236 KB)
Steven Van Vaerenbergh
Last modified: 2010-08-07