Spectral clustering
Spectral clustering [9] is a recently proposed successful
method rooted in graph theory [11], capable of clustering
data based on point-to-point similarities. For most problems,
``similarity'' is measured as the distance between data points,
defining clusters as connected zones of points and making it
possible to easily cluster non-convex data sets, as illustrated by
Fig. 2.
Figure 2:
(a) Two sets of intertwined data points, difficult or
impossible to cluster with conventional clustering algorithms. (b)
Spectral clustering easily divides the points in two separate
groups, based on the principle that two points should be in the same
group if they are close to each other.
 |
 |
| (a) |
(b) |
|
The similarity between two points
![$ \textbf{x}[i]$](img27.png) and
and
![$ \textbf{x}[j]$](img28.png) is measured through a kernel function
is measured through a kernel function 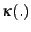 such as
such as
![$\displaystyle \kappa(\textbf{x}[i],\textbf{x}[j]) =
\exp\left(-\frac{d^2(\textbf{x}[i],\textbf{x}[j])}{\sigma^2}\right)$](img30.png) |
(3) |
where
![$ d(\textbf{x}[i],\textbf{x}[j])$](img31.png) is some distance measure
between points
and
and
is some distance measure
between points
and
and 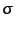 is
the kernel size. This kernel function is almost
is
the kernel size. This kernel function is almost  for points that
are close to each other, and lowers as the distance rises.
for points that
are close to each other, and lowers as the distance rises.
Given a set of  points
points
![$ \{\textbf{x}[1], \textbf{x}[2], \dots,
\textbf{x}[N]\}$](img35.png) , a similarity matrix (also called ``affinity'' or
kernel matrix) can be defined as
, a similarity matrix (also called ``affinity'' or
kernel matrix) can be defined as
![$ A_{ij} =
\kappa(\textbf{x}[i],\textbf{x}[j])$](img36.png) . Clustering is performed by
analyzing the spectrum of that matrix. One of the most successful
spectral clustering algorithms is the Ng-Jordan-Weiss (NJW)
algorithm, introduced in [9]. It can be summarized as
follows:
. Clustering is performed by
analyzing the spectrum of that matrix. One of the most successful
spectral clustering algorithms is the Ng-Jordan-Weiss (NJW)
algorithm, introduced in [9]. It can be summarized as
follows:
- Calculate the affinity matrix A using
(3), and set
 for
for
 .
.
- Obtain
 , where
, where  is a diagonal matrix with
is a diagonal matrix with
 . This normalization will assure that all clusters have more or less equal size.
. This normalization will assure that all clusters have more or less equal size.
- Form the matrix
![$ V = [v_1,v_2,\dots,v_k]$](img42.png) where
where
 are the
are the  largest eigenvectors of
largest eigenvectors of  and
is the number of
subsets to retrieve.
and
is the number of
subsets to retrieve.
- Treat the rows of
 as points in
as points in
 , and
normalize them to unit length. These points correspond to the
original points
but form compact clusters now. Cluster them
with an algorithm such as k-means.
, and
normalize them to unit length. These points correspond to the
original points
but form compact clusters now. Cluster them
with an algorithm such as k-means.
- Assign the original point
to cluster
 if and only
if row
if and only
if row  of the matrix
was assigned to
cluster
.
of the matrix
was assigned to
cluster
.
Steven Van Vaerenbergh
Last modified: 2007-10-17