Discarding criterion
In the 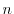 -th iteration, the pattern
-th iteration, the pattern
 is first added to the memory, which now contains
is first added to the memory, which now contains  patterns. The inverse kernel matrix is updated as described in section 3.1.1, and
the regression coefficients
patterns. The inverse kernel matrix is updated as described in section 3.1.1, and
the regression coefficients  can be recalculated according to (4). In this section we discuss a criterion that determines the least significant of the stored
patterns. Once it is found, the kernel matrix is downsized as in Alg. 1, and is recalculated through (4).
can be recalculated according to (4). In this section we discuss a criterion that determines the least significant of the stored
patterns. Once it is found, the kernel matrix is downsized as in Alg. 1, and is recalculated through (4).
Ideally, the pruning criterion should take into account the information present in the stored input data
 and the stored labels
and the stored labels  . A simple criterion consists in selecting the pattern that bears least error after it is omitted. As shown in [7], this error can be obtained as
. A simple criterion consists in selecting the pattern that bears least error after it is omitted. As shown in [7], this error can be obtained as
![$\displaystyle d({\mathbf x}_i,y_i) = \frac{\vert\alpha_i\vert}{[\breve{{\mathbf K}}_n^{-1}]_{i,i}},$](img60.png) |
(8) |
which is easily found since
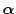 and
and
 have been calculated previously. Moreover, experiments in [7,8] show that this criterion obtains significant better performance than various related criteria.
have been calculated previously. Moreover, experiments in [7,8] show that this criterion obtains significant better performance than various related criteria.
 Pdf version (236 KB)
Pdf version (236 KB)
Steven Van Vaerenbergh
Last modified: 2010-08-07