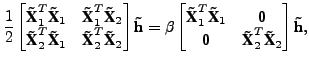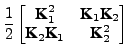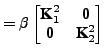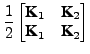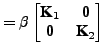Although CCA constitutes a good technique to find linear
relationships between two or several [17] data
sets, it is not able to extract nonlinear relationships. In order
to solve this problem, CCA has been extended to nonlinear CCA and
kernel-CCA (K-CCA) [11,12,19].
Specifically, kernel CCA exploits the characteristics of kernel
methods, consisting in the implicit nonlinear transformation of
the data
![]() from the input space to a high dimensional
feature space
from the input space to a high dimensional
feature space
![]() . Then, solving
CCA in the feature space we are able to extract nonlinear
relationships.
. Then, solving
CCA in the feature space we are able to extract nonlinear
relationships.
The key property of the kernel methods and reproducing kernel
Hilbert spaces (RKHS) is that, since the scalar products in the
feature space can be seen as nonlinear (kernel) functions of the
data in the input space, the explicit mapping to the feature space
can be avoided, and any linear technique can be performed in the
feature space by solely replacing the scalar products by the
kernel function in the input space. In this way, any positive
definite kernel function satisfying Mercer's condition
[20]:
![]() has an
implicit mapping to some higher-dimensional feature space. This
simple and elegant idea is known as the ``kernel trick'', and it
is commonly applied by using a nonlinear kernel such as the
Gaussian kernel
has an
implicit mapping to some higher-dimensional feature space. This
simple and elegant idea is known as the ``kernel trick'', and it
is commonly applied by using a nonlinear kernel such as the
Gaussian kernel
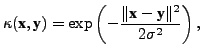 |
After transforming the data and canonical vectors to feature space, the GEV problem (3) can be written as
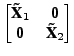 |
To summarize, the application of the kernel trick permits the solution of the CCA problem in the feature space without increasing the computational cost and conserving the LS regression framework.