In a Bayesian setting, we need a model that describes the observations, and priors on the parameters of such model. Following the standard setup of GP regression, we can describe observations as the sum of an unobservable latent function of the inputs plus zero-mean Gaussian noise
 |
(1) |
In order to perform Bayesian inference, we also need a prior over the latent function, which is taken to be a zero-mean GP with covariance function
 . The use of a GP prior has a simple meaning: It implies that the prior joint distribution of vector
. The use of a GP prior has a simple meaning: It implies that the prior joint distribution of vector
![$ {\boldsymbol{\mathbf{f}}}_t = [f_1,\ldots, f_t]^\top$](img17.png) (where
(where
 ) is a zero-mean multivariate Gaussian with covariance matrix
) is a zero-mean multivariate Gaussian with covariance matrix
 , with elements
, with elements
![$ [{\boldsymbol{\mathbf{K}}}_t]_{ij} = k({\boldsymbol{\mathbf{x}}}_i,{\boldsymbol{\mathbf{x}}}_j)$](img20.png) . In line with the previous literature on KRLS, we will refer to
as the kernel function, and to
as the kernel matrix (which in this example would correspond to inputs
. In line with the previous literature on KRLS, we will refer to
as the kernel function, and to
as the kernel matrix (which in this example would correspond to inputs
 ). For the sake of clarity, in the following we will omit conditioning on the inputs
). For the sake of clarity, in the following we will omit conditioning on the inputs
 or the parameters
or the parameters
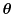 that parameterize the kernel function.
that parameterize the kernel function.
 Pdf version (275 KB)
Pdf version (275 KB)
Steven Van Vaerenbergh
Last modified: 2011-09-20